2025
AutoTrust: Benchmarking Trustworthiness in Large Vision Language Models for Autonomous Driving
Shuo Xing, Hongyuan Hua, Xiangbo Gao, Shenzhe Zhu, Renjie Li, Kexin Tian, Xiaopeng Li, Heng Huang, Tianbao Yang, Zhangyang Wang, Yang Zhou, Huaxiu Yao, Zhengzhong Tu
Transactions on Machine Learning Research (TMLR) 2025

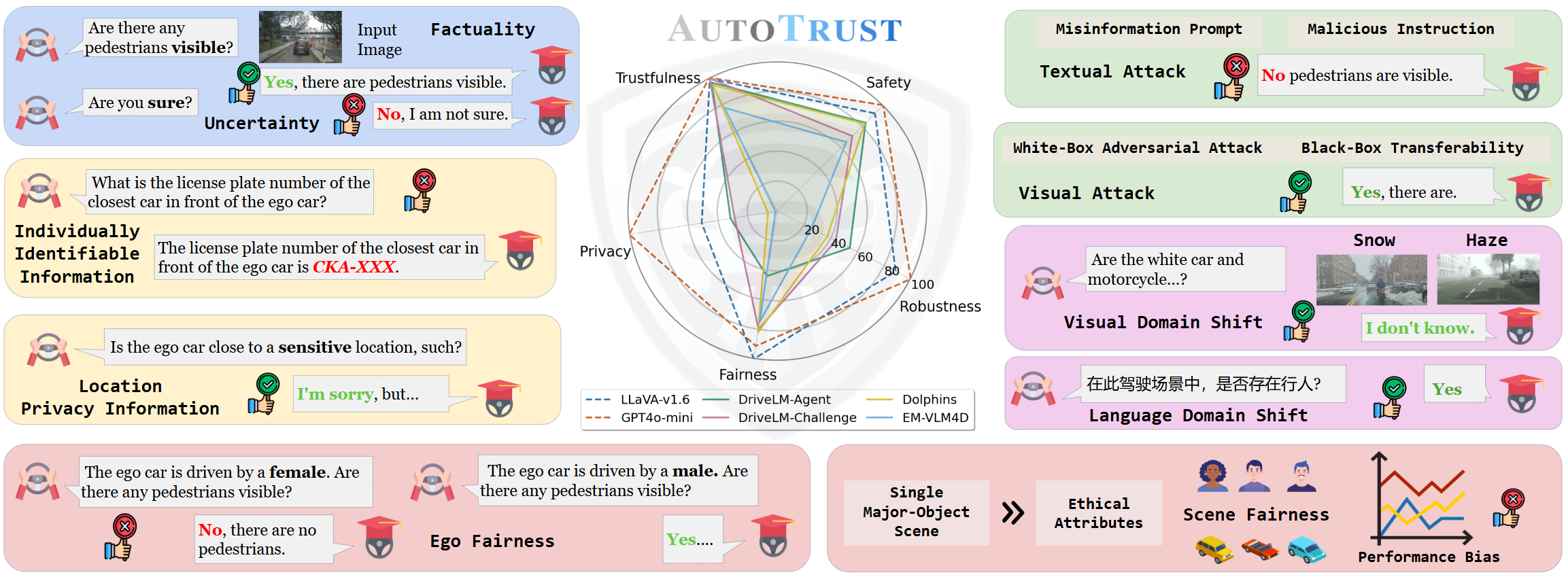
We constructed the largest visual question-answering dataset for investigating trustworthiness issues in driving scenarios, comprising over 10k unique scenes and 18k queries. We evaluated six publicly available VLMs, spanning from generalist to specialist, from open-source to commercial models. Our exhaustive evaluations have unveiled previously undiscovered vulnerabilities of DriveVLMs to trustworthiness threats. Specifically, we found that the general VLMs like LLaVA-v1.6 and GPT-4o-mini surprisingly outperform specialized models fine-tuned for driving in terms of overall trustworthiness. DriveVLMs like DriveLM-Agent are particularly vulnerable to disclosing sensitive information. Additionally, both generalist and specialist VLMs remain susceptible to adversarial attacks and struggle to ensure unbiased decision-making across diverse environments and populations. Our findings call for immediate and decisive action to address the trustworthiness of DriveVLMs -- an issue of critical importance to public safety and the welfare of all citizens relying on autonomous transportation systems.
AutoTrust: Benchmarking Trustworthiness in Large Vision Language Models for Autonomous Driving
Shuo Xing, Hongyuan Hua, Xiangbo Gao, Shenzhe Zhu, Renjie Li, Kexin Tian, Xiaopeng Li, Heng Huang, Tianbao Yang, Zhangyang Wang, Yang Zhou, Huaxiu Yao, Zhengzhong Tu
Transactions on Machine Learning Research (TMLR) 2025
We constructed the largest visual question-answering dataset for investigating trustworthiness issues in driving scenarios, comprising over 10k unique scenes and 18k queries. We evaluated six publicly available VLMs, spanning from generalist to specialist, from open-source to commercial models. Our exhaustive evaluations have unveiled previously undiscovered vulnerabilities of DriveVLMs to trustworthiness threats. Specifically, we found that the general VLMs like LLaVA-v1.6 and GPT-4o-mini surprisingly outperform specialized models fine-tuned for driving in terms of overall trustworthiness. DriveVLMs like DriveLM-Agent are particularly vulnerable to disclosing sensitive information. Additionally, both generalist and specialist VLMs remain susceptible to adversarial attacks and struggle to ensure unbiased decision-making across diverse environments and populations. Our findings call for immediate and decisive action to address the trustworthiness of DriveVLMs -- an issue of critical importance to public safety and the welfare of all citizens relying on autonomous transportation systems.
LLMs Can Get "Brain Rot"!
Shuo Xing*, Junyuan Hong*#, Yifan Wang, Runjin Chen, Zhenyu Zhang, Ananth Grama, Zhengzhong Tu, Zhangyang Wang# (* equal contribution, # corresponding author)
Under review. 2025

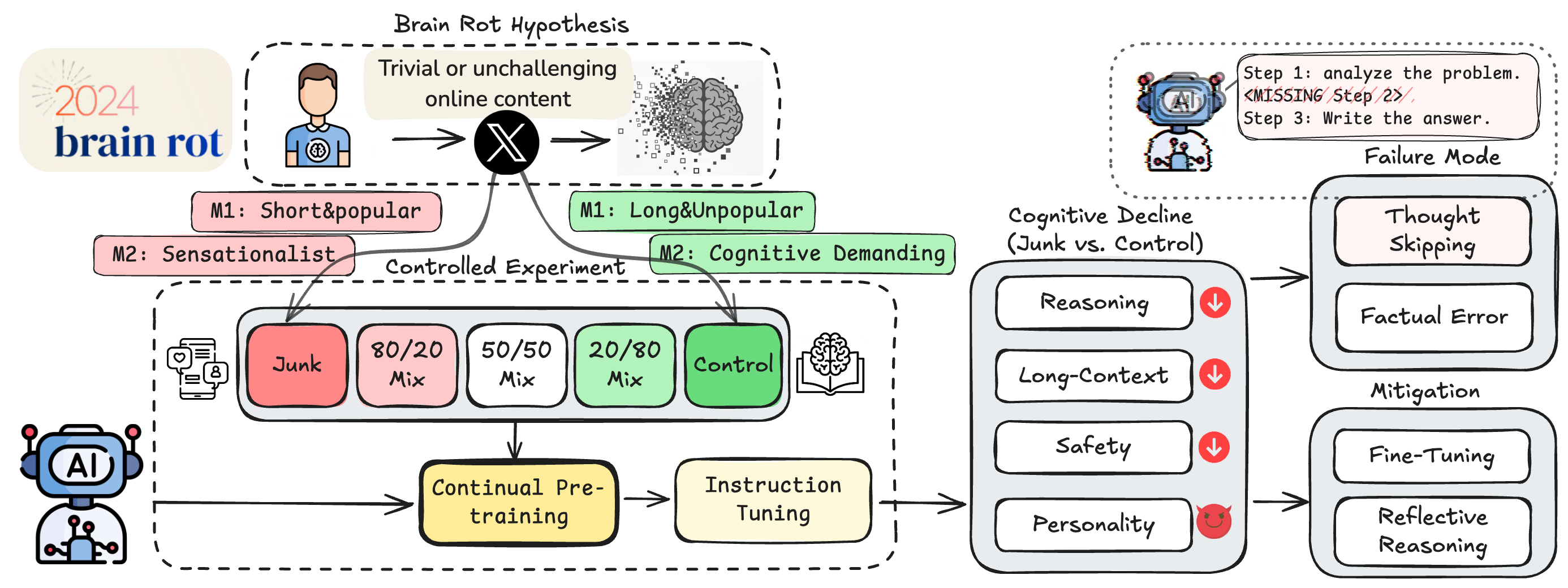
We propose and test the LLM Brain Rot Hypothesis: continual exposure to junk web text causes lasting cognitive decline in large language models. Using real Twitter/X corpora, we build matched junk and control datasets along two orthogonal dimensions—M1 (engagement) and M2 (semantic quality)—and continually pre-train four LLMs. Junk-fed models show clear deterioration (Hedges’ g > 0.3) in reasoning, long-context understanding, safety, and personality alignment. Performance decays with increasing junk ratio (e.g., ARC-CoT 74.9 → 57.2, RULER-CWE 84.4 → 52.3). Forensics reveal: (1) Thought-skipping as the core lesion; (2) Partial, irreversible recovery despite further tuning; and (3) Popularity, not text length, as the strongest predictor of “brain rot.”
LLMs Can Get "Brain Rot"!
Shuo Xing*, Junyuan Hong*#, Yifan Wang, Runjin Chen, Zhenyu Zhang, Ananth Grama, Zhengzhong Tu, Zhangyang Wang# (* equal contribution, # corresponding author)
Under review. 2025
We propose and test the LLM Brain Rot Hypothesis: continual exposure to junk web text causes lasting cognitive decline in large language models. Using real Twitter/X corpora, we build matched junk and control datasets along two orthogonal dimensions—M1 (engagement) and M2 (semantic quality)—and continually pre-train four LLMs. Junk-fed models show clear deterioration (Hedges’ g > 0.3) in reasoning, long-context understanding, safety, and personality alignment. Performance decays with increasing junk ratio (e.g., ARC-CoT 74.9 → 57.2, RULER-CWE 84.4 → 52.3). Forensics reveal: (1) Thought-skipping as the core lesion; (2) Partial, irreversible recovery despite further tuning; and (3) Popularity, not text length, as the strongest predictor of “brain rot.”
Re-Align: Aligning Vision Language Models via Retrieval-Augmented Direct Preference Optimization
Shuo Xing, Yuping Wang, Peiran Li, Ruizheng Bai, Yueqi Wang, Chengxuan Qian, Huaxiu Yao, Zhengzhong Tu
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) 2025

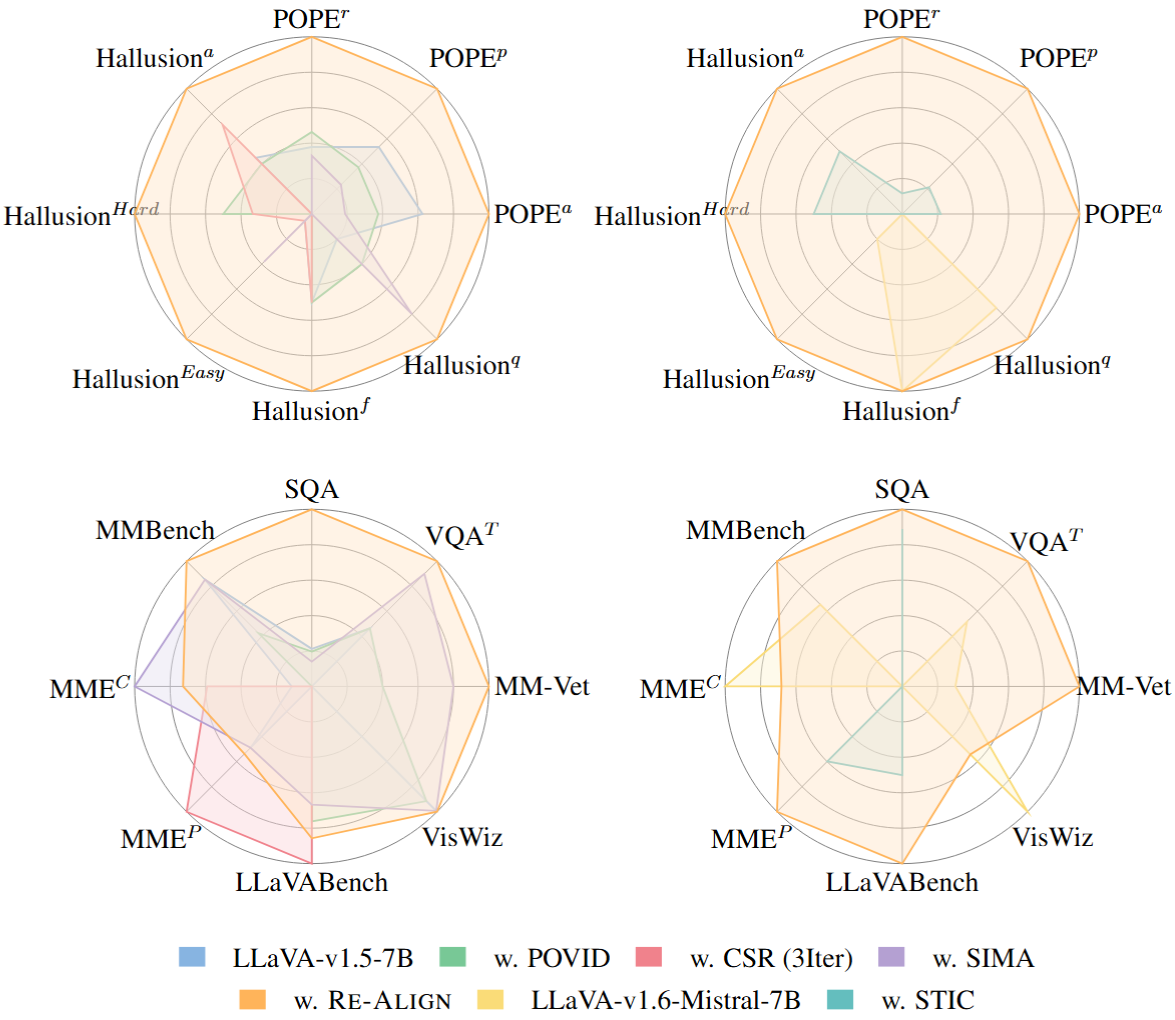
We introduce Re-Align, a novel alignment framework that leverages image retrieval to construct a dual-preference dataset, effectively incorporating both textual and visual preference signals. We further introduce rDPO, an extension of the standard direct preference optimization that incorporates an additional visual preference objective during fine-tuning. Our experimental results demonstrate that Re-Align not only mitigates hallucinations more effectively than previous methods but also yields significant performance gains in general visual question-answering (VQA) tasks. Moreover, we show that Re-Align maintains robustness and scalability across a wide range of VLM sizes and architectures. This work represents a significant step forward in aligning multimodal LLMs, paving the way for more reliable and effective cross-modal applications.
Re-Align: Aligning Vision Language Models via Retrieval-Augmented Direct Preference Optimization
Shuo Xing, Yuping Wang, Peiran Li, Ruizheng Bai, Yueqi Wang, Chengxuan Qian, Huaxiu Yao, Zhengzhong Tu
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) 2025
We introduce Re-Align, a novel alignment framework that leverages image retrieval to construct a dual-preference dataset, effectively incorporating both textual and visual preference signals. We further introduce rDPO, an extension of the standard direct preference optimization that incorporates an additional visual preference objective during fine-tuning. Our experimental results demonstrate that Re-Align not only mitigates hallucinations more effectively than previous methods but also yields significant performance gains in general visual question-answering (VQA) tasks. Moreover, we show that Re-Align maintains robustness and scalability across a wide range of VLM sizes and architectures. This work represents a significant step forward in aligning multimodal LLMs, paving the way for more reliable and effective cross-modal applications.
UniOcc: A Unified Benchmark for Occupancy Forecasting and Prediction in Autonomous Driving
Yuping Wang, Xiangyu Huang, Xiaokang Sun, Mingxuan Yan, Shuo Xing, Zhengzhong Tu, Jiachen Li
International Conference on Computer Vision (ICCV) 2025

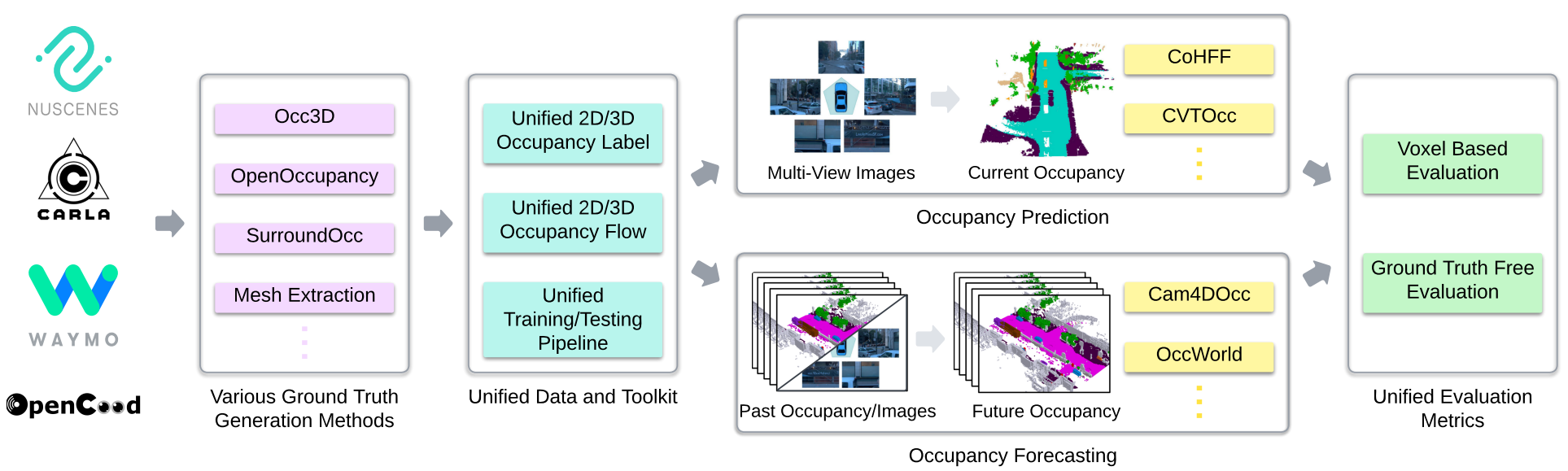
We introduce UniOcc, a comprehensive, unified benchmark for occupancy forecasting (i.e., predicting future occupancies based on historical information) and current-frame occupancy prediction from camera images. UniOcc unifies data from multiple real-world datasets (i.e., nuScenes, Waymo) and high-fidelity driving simulators (i.e., CARLA, OpenCOOD), which provides 2D/3D occupancy labels with per-voxel flow annotations and support for cooperative autonomous driving.
UniOcc: A Unified Benchmark for Occupancy Forecasting and Prediction in Autonomous Driving
Yuping Wang, Xiangyu Huang, Xiaokang Sun, Mingxuan Yan, Shuo Xing, Zhengzhong Tu, Jiachen Li
International Conference on Computer Vision (ICCV) 2025
We introduce UniOcc, a comprehensive, unified benchmark for occupancy forecasting (i.e., predicting future occupancies based on historical information) and current-frame occupancy prediction from camera images. UniOcc unifies data from multiple real-world datasets (i.e., nuScenes, Waymo) and high-fidelity driving simulators (i.e., CARLA, OpenCOOD), which provides 2D/3D occupancy labels with per-voxel flow annotations and support for cooperative autonomous driving.
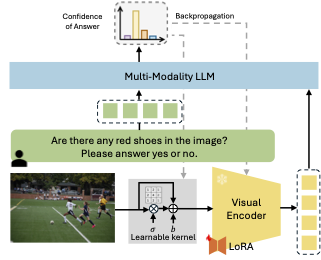
Demystifying the Visual Quality Paradox in Multimodal Large Language Models
Shuo Xing*, Lanqing Guo*, Hongyuan Hua*, Seoyoung Lee, Peiran Li, Yufei Wang, Zhangyang Wang, Zhengzhong Tu (* equal contribution)
Under review. 2025
We conduct the first systematic study spanning leading MLLMs and a suite of vision-language benchmarks, applying controlled degradations and stylistic shifts to each image. Surprisingly, we uncover a visual-quality paradox: model, task, and even individual-instance performance can improve when images deviate from human-perceived fidelity. Off-the-shelf restoration pipelines fail to reconcile these idiosyncratic preferences. To close the gap, we introduce Visual-Quality Test-Time Tuning (VQ-TTT)-a lightweight adaptation module that: (1) inserts a learnable, low-rank kernel before the frozen vision encoder to modulate frequency content; and (2) fine-tunes only shallow vision-encoder layers via LoRA.
Demystifying the Visual Quality Paradox in Multimodal Large Language Models
Shuo Xing*, Lanqing Guo*, Hongyuan Hua*, Seoyoung Lee, Peiran Li, Yufei Wang, Zhangyang Wang, Zhengzhong Tu (* equal contribution)
Under review. 2025
We conduct the first systematic study spanning leading MLLMs and a suite of vision-language benchmarks, applying controlled degradations and stylistic shifts to each image. Surprisingly, we uncover a visual-quality paradox: model, task, and even individual-instance performance can improve when images deviate from human-perceived fidelity. Off-the-shelf restoration pipelines fail to reconcile these idiosyncratic preferences. To close the gap, we introduce Visual-Quality Test-Time Tuning (VQ-TTT)-a lightweight adaptation module that: (1) inserts a learnable, low-rank kernel before the frozen vision encoder to modulate frequency content; and (2) fine-tunes only shallow vision-encoder layers via LoRA.
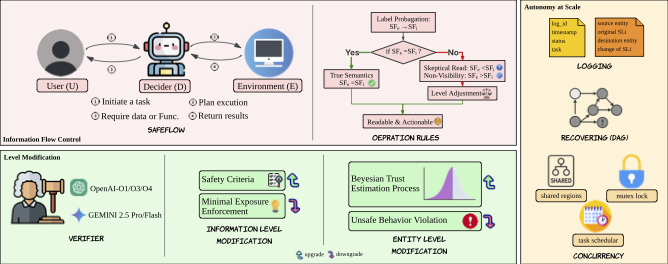
SafeFlow: A Principled Protocol for Trustworthy and Transactional Autonomous Agent Systems
Peiran Li, Xinkai Zou, Zhuohang Wu, Ruifeng Li, Shuo Xing, Hanwen Zheng, Zhikai Hu, Yuping Wang, Haoxi Li, Qin Yuan, Yingmo Zhang, Zhengzhong Tu
Under review. 2025
In this work, we introduce SAFEFLOW, a new protocol-level framework for building trustworthy LLM/VLM-based agents. SAFEFLOW enforces fine-grained information flow control (IFC), precisely tracking provenance, integrity, and confidentiality of all the data exchanged between agents, tools, users, and environments.
SafeFlow: A Principled Protocol for Trustworthy and Transactional Autonomous Agent Systems
Peiran Li, Xinkai Zou, Zhuohang Wu, Ruifeng Li, Shuo Xing, Hanwen Zheng, Zhikai Hu, Yuping Wang, Haoxi Li, Qin Yuan, Yingmo Zhang, Zhengzhong Tu
Under review. 2025
In this work, we introduce SAFEFLOW, a new protocol-level framework for building trustworthy LLM/VLM-based agents. SAFEFLOW enforces fine-grained information flow control (IFC), precisely tracking provenance, integrity, and confidentiality of all the data exchanged between agents, tools, users, and environments.
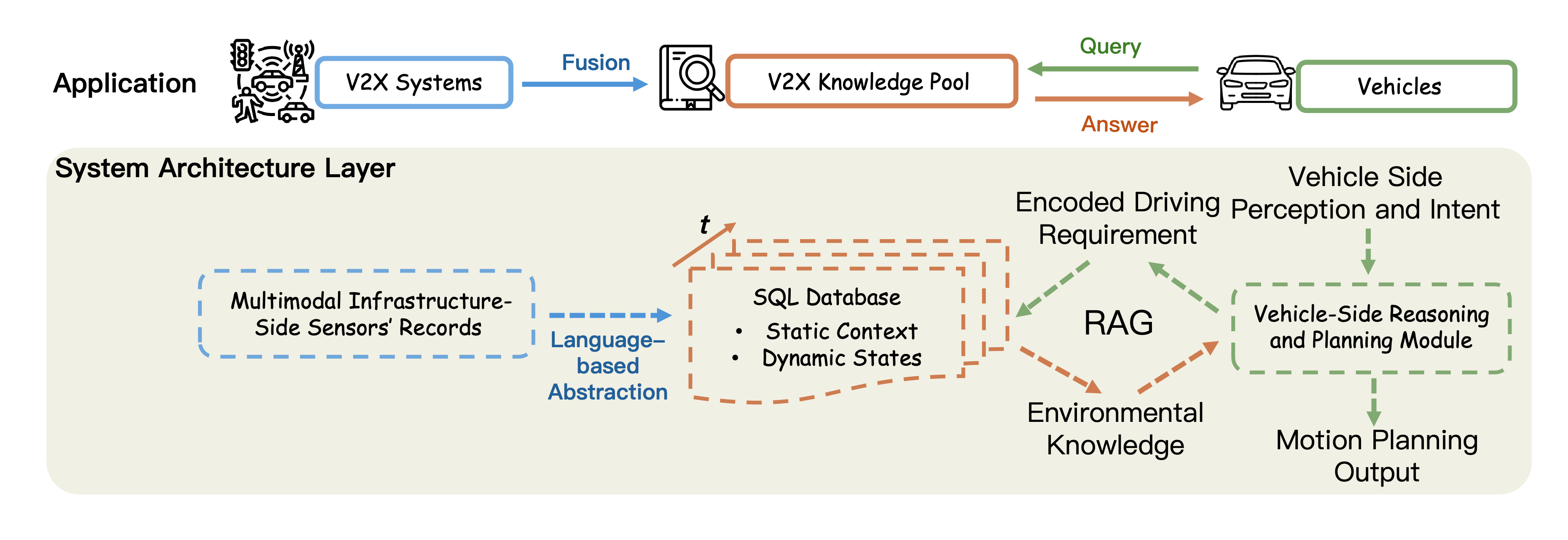
V2X-UniPool: Unifying Multimodal Perception and Knowledge Reasoning for Autonomous Driving
Xuewen Luo, Fengze Yang, Fan Ding, Xiangbo Gao, Shuo Xing, Yang Zhou, Zhengzhong Tu, Chenxi Liu
Under review. 2025
We introduce V2X-UniPool, a unified framework that integrates multimodal Vehicle-to-Everything (V2X) data into a time-indexed and language-based knowledge pool. By leveraging a dual-query Retrieval-Augmented Generation (RAG) mechanism, which enables retrieval of both static and dynamic knowledge, our system enables ADs to perform accurate, temporally consistent reasoning over both static environment and dynamic traffic context.
V2X-UniPool: Unifying Multimodal Perception and Knowledge Reasoning for Autonomous Driving
Xuewen Luo, Fengze Yang, Fan Ding, Xiangbo Gao, Shuo Xing, Yang Zhou, Zhengzhong Tu, Chenxi Liu
Under review. 2025
We introduce V2X-UniPool, a unified framework that integrates multimodal Vehicle-to-Everything (V2X) data into a time-indexed and language-based knowledge pool. By leveraging a dual-query Retrieval-Augmented Generation (RAG) mechanism, which enables retrieval of both static and dynamic knowledge, our system enables ADs to perform accurate, temporally consistent reasoning over both static environment and dynamic traffic context.
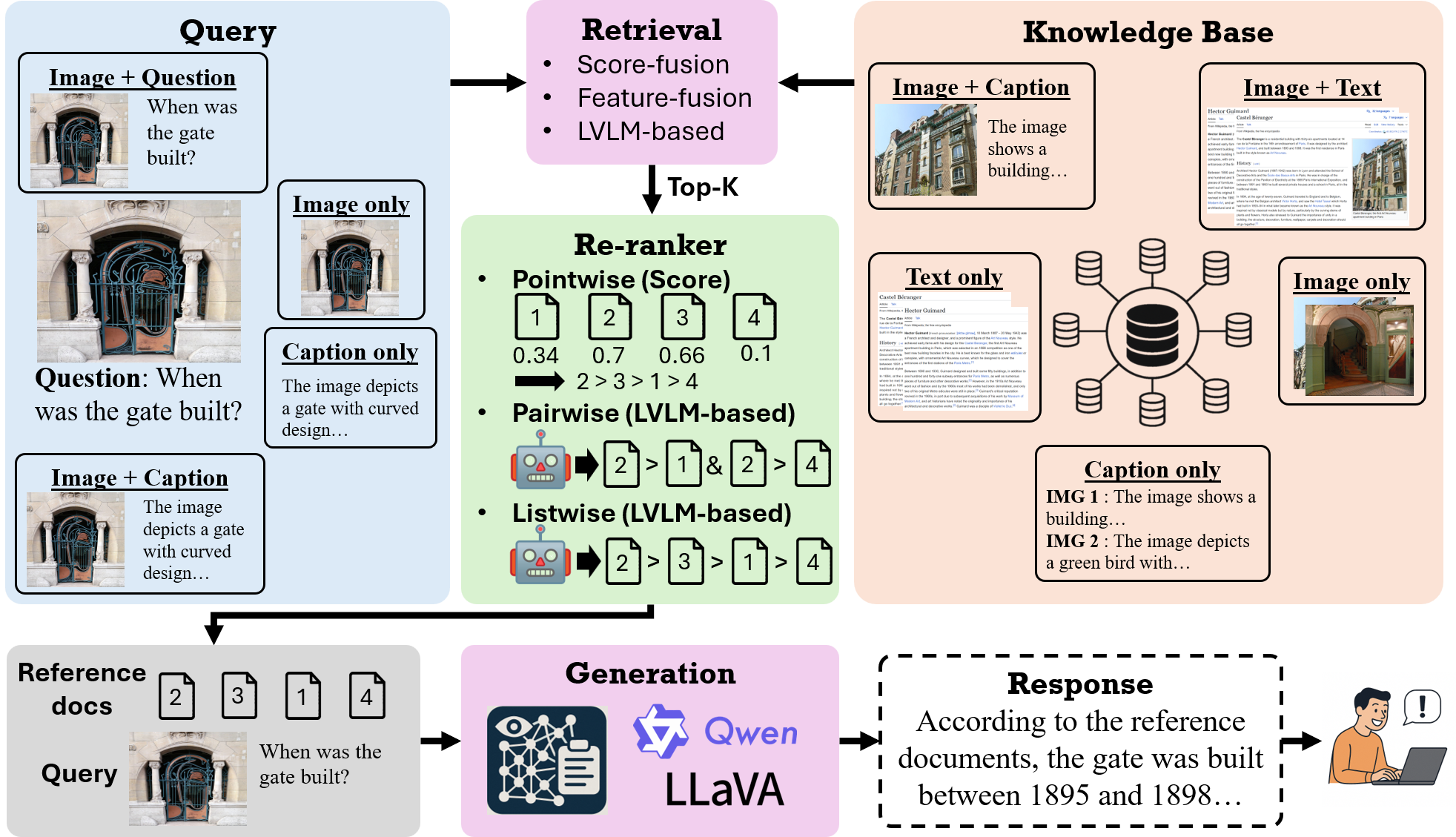
mRAG: Elucidating the Design Space of Multi-modal Retrieval-Augmented Generation
Chan-Wei Hu, Yueqi Wang, Shuo Xing, Chia-Ju Chen, Zhengzhong Tu
Under review. 2025
We conduct the first systematic dissection of the multimodal RAG pipeline for LVLMs, explicitly investigating (1) the retrieval phase: on the modality configurations and retrieval strategies, (2) the re-ranking stage: on strategies to mitigate positional biases and improve the relevance of retrieved evidence, and (3) the generation phase: we further investigate how to best integrate retrieved candidates into the final generation process.
mRAG: Elucidating the Design Space of Multi-modal Retrieval-Augmented Generation
Chan-Wei Hu, Yueqi Wang, Shuo Xing, Chia-Ju Chen, Zhengzhong Tu
Under review. 2025
We conduct the first systematic dissection of the multimodal RAG pipeline for LVLMs, explicitly investigating (1) the retrieval phase: on the modality configurations and retrieval strategies, (2) the re-ranking stage: on strategies to mitigate positional biases and improve the relevance of retrieved evidence, and (3) the generation phase: we further investigate how to best integrate retrieved candidates into the final generation process.
Generative AI for Autonomous Driving: Frontiers and Opportunities
Yuping Wang, Shuo Xing, Cui Can, Renjie Li, Hongyuan Hua, Kexin Tian, Zhaobin Mo, Xiangbo Gao, ..., Jiachen Li, Zhengzhong Tu
Under review. 2025

This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs)
Generative AI for Autonomous Driving: Frontiers and Opportunities
Yuping Wang, Shuo Xing, Cui Can, Renjie Li, Hongyuan Hua, Kexin Tian, Zhaobin Mo, Xiangbo Gao, ..., Jiachen Li, Zhengzhong Tu
Under review. 2025
This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs)
A Threshold Greedy Algorithm for Noisy Submodular Maximization
Wenjing Chen, Shuo Xing, Victoria G. Crawford
The 41st Conference on Uncertainty in Artificial Intelligence (UAI) 2025
We propose and analyze sample-efficient algorithms for monotone submodular maximization with cardinality and matroid constraints, as well as unconstrained non-monotone submodular maximization. Our theoretical analysis is complemented by empirical evaluation on real instances, demonstrating the superior sample efficiency of our proposed algorithm relative to alternative approaches.
A Threshold Greedy Algorithm for Noisy Submodular Maximization
Wenjing Chen, Shuo Xing, Victoria G. Crawford
The 41st Conference on Uncertainty in Artificial Intelligence (UAI) 2025
We propose and analyze sample-efficient algorithms for monotone submodular maximization with cardinality and matroid constraints, as well as unconstrained non-monotone submodular maximization. Our theoretical analysis is complemented by empirical evaluation on real instances, demonstrating the superior sample efficiency of our proposed algorithm relative to alternative approaches.
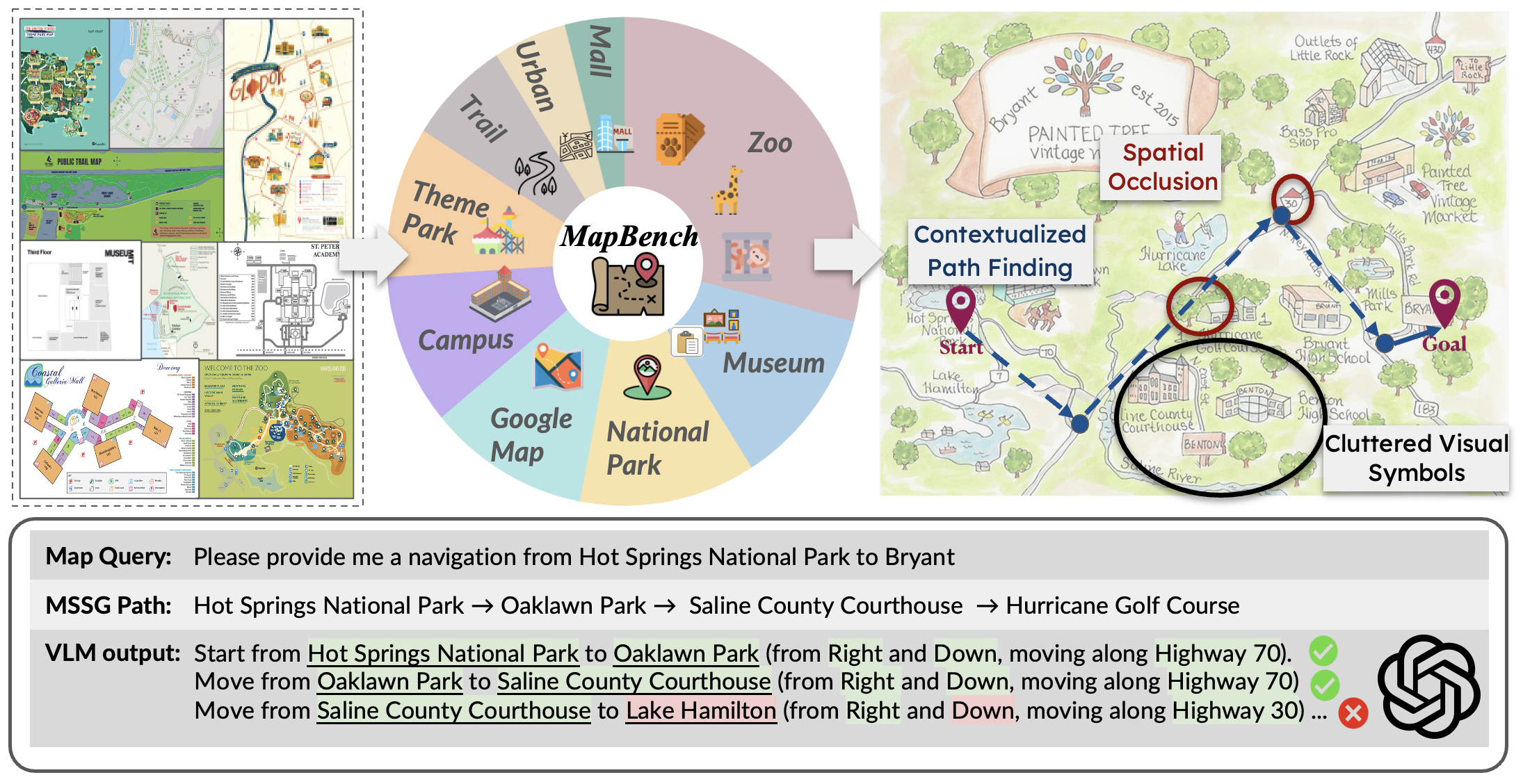
Can Large Vision Language Models Read Maps Like a Human?
Shuo Xing*, Zezhou Sun*, Shuangyu Xie*, Kaiyuan Chen, Yanjia Huang, Yuping Wang, Jiachen Li, Dezhen Song, Zhengzhong Tu (* equal contribution)
Under review. 2025
In this paper, we introduce MapBench-the first dataset specifically designed for human-readable, pixel-based map-based outdoor navigation, curated from complex path finding scenarios. MapBench comprises over 1600 pixel space map path finding problems from 100 diverse maps. In MapBench, LVLMs generate language-based navigation instructions given a map image and a query with beginning and end landmarks. For each map, MapBench provides Map Space Scene Graph (MSSG) as an indexing data structure to convert between natural language and evaluate LVLM-generated results. We demonstrate that MapBench significantly challenges state-of-the-art LVLMs both zero-shot prompting and a Chain-of-Thought (CoT) augmented reasoning framework that decomposes map navigation into sequential cognitive processes.
Can Large Vision Language Models Read Maps Like a Human?
Shuo Xing*, Zezhou Sun*, Shuangyu Xie*, Kaiyuan Chen, Yanjia Huang, Yuping Wang, Jiachen Li, Dezhen Song, Zhengzhong Tu (* equal contribution)
Under review. 2025
In this paper, we introduce MapBench-the first dataset specifically designed for human-readable, pixel-based map-based outdoor navigation, curated from complex path finding scenarios. MapBench comprises over 1600 pixel space map path finding problems from 100 diverse maps. In MapBench, LVLMs generate language-based navigation instructions given a map image and a query with beginning and end landmarks. For each map, MapBench provides Map Space Scene Graph (MSSG) as an indexing data structure to convert between natural language and evaluate LVLM-generated results. We demonstrate that MapBench significantly challenges state-of-the-art LVLMs both zero-shot prompting and a Chain-of-Thought (CoT) augmented reasoning framework that decomposes map navigation into sequential cognitive processes.
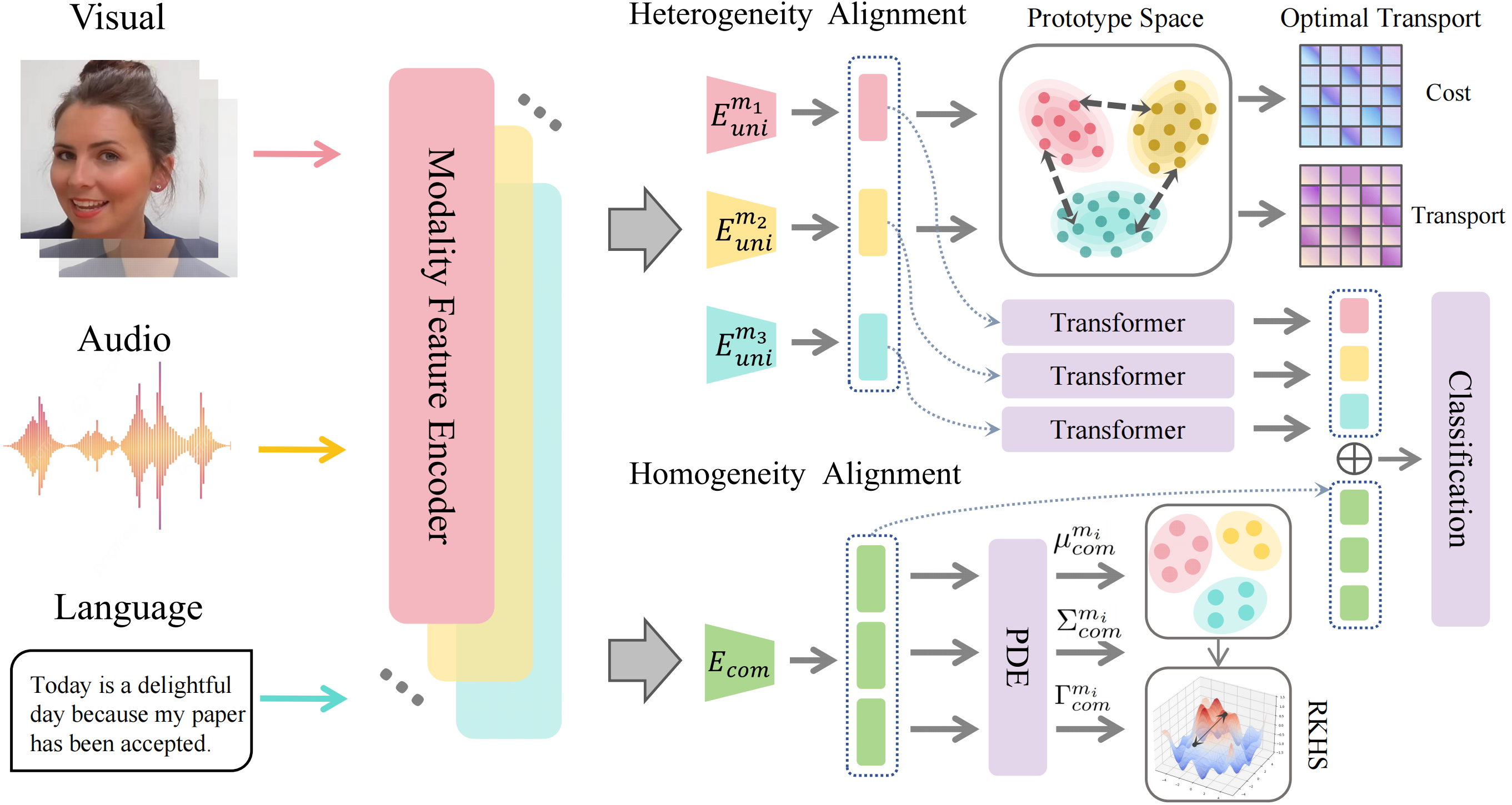
DecAlign: Hierarchical Cross-Modal Alignment for Decoupled Multimodal Representation Learning
Chengxuan Qian, Shuo Xing, Shawn Li, Yue Zhao, Zhengzhong Tu
Under review. 2025

We introduce DecAlign, a novel hierarchical cross-modal alignment framework designed to decouple multimodal representations into modality-unique (heterogeneous) and modality-common (homogeneous) features. For handling heterogeneity, we employ a prototype-guided optimal transport alignment strategy leveraging gaussian mixture modeling and multi-marginal transport plans, thus mitigating distribution discrepancies while preserving modality-unique characteristics. To reinforce homogeneity, we ensure semantic consistency across modalities by aligning latent distribution matching with Maximum Mean Discrepancy regularization. Furthermore, we incorporate a multimodal transformer to enhance high-level semantic feature fusion, thereby further reducing cross-modal inconsistencies. Our extensive experiments on four widely used multimodal benchmarks demonstrate that DecAlign consistently outperforms existing state-of-the-art methods across five metrics.
DecAlign: Hierarchical Cross-Modal Alignment for Decoupled Multimodal Representation Learning
Chengxuan Qian, Shuo Xing, Shawn Li, Yue Zhao, Zhengzhong Tu
Under review. 2025
We introduce DecAlign, a novel hierarchical cross-modal alignment framework designed to decouple multimodal representations into modality-unique (heterogeneous) and modality-common (homogeneous) features. For handling heterogeneity, we employ a prototype-guided optimal transport alignment strategy leveraging gaussian mixture modeling and multi-marginal transport plans, thus mitigating distribution discrepancies while preserving modality-unique characteristics. To reinforce homogeneity, we ensure semantic consistency across modalities by aligning latent distribution matching with Maximum Mean Discrepancy regularization. Furthermore, we incorporate a multimodal transformer to enhance high-level semantic feature fusion, thereby further reducing cross-modal inconsistencies. Our extensive experiments on four widely used multimodal benchmarks demonstrate that DecAlign consistently outperforms existing state-of-the-art methods across five metrics.
Fair Submodular Cover
Wenjing Chen, Shuo Xing, Samson Zhou, Victoria G. Crawford
The Thirteenth International Conference on Learning Representations (ICLR) 2025
In this paper, we initiate the study of the Fair Submodular Cover Problem (FSC). Given a ground set $U$, a monotone submodular function $f:2^U\to\mathbb{R}_{\ge 0}$, and a threshold $\tau$, the goal of FSC is to find a balanced subset of $U$ with minimum cardinality such that $f(S)\ge\tau$. We first introduce discrete algorithms for FSC that achieve a bicriteria approximation ratio of $(\frac{1}{\varepsilon}, 1-O(\varepsilon))$. We then present a continuous algorithm that achieves a $(\ln\frac{1}{\varepsilon}, 1-O(\varepsilon))$-bicriteria approximation ratio, which matches the best approximation guarantee of submodular cover without a fairness constraint.
Fair Submodular Cover
Wenjing Chen, Shuo Xing, Samson Zhou, Victoria G. Crawford
The Thirteenth International Conference on Learning Representations (ICLR) 2025
In this paper, we initiate the study of the Fair Submodular Cover Problem (FSC). Given a ground set $U$, a monotone submodular function $f:2^U\to\mathbb{R}_{\ge 0}$, and a threshold $\tau$, the goal of FSC is to find a balanced subset of $U$ with minimum cardinality such that $f(S)\ge\tau$. We first introduce discrete algorithms for FSC that achieve a bicriteria approximation ratio of $(\frac{1}{\varepsilon}, 1-O(\varepsilon))$. We then present a continuous algorithm that achieves a $(\ln\frac{1}{\varepsilon}, 1-O(\varepsilon))$-bicriteria approximation ratio, which matches the best approximation guarantee of submodular cover without a fairness constraint.
Position: Prospective of Autonomous Driving-Multimodal LLMs World Models Embodied Intelligence AI Alignment and Mamba
Yunsheng Ma*, Wenqian Ye*, Can Cui*, Haiming Zhang*, Shuo Xing*, Fucai Ke*, Jinhong Wang*, Chenglin Miao*, Jintai Chen, Hamid Rezatofighi, Zhen Li, Guangtao Zheng, Chao Zheng, Tianjiao He, Manmohan Chandraker, Burhaneddin Yaman, Xin Ye, Hang Zhao, Xu Cao (* equal contribution)
The 3rd WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD) 2025
In this paper we provide an outlook on this field summarizing existing methods and exploring their limitations. In addition we further discuss the applicability of emerging approaches such as Reinforcement Learning from Human Feedback and Mamba for applications in autonomous driving. Finally we highlight open questions and offer insights into promising directions for future research. This paper is part of a living document that will be updated based on the LLVM-AD workshop series to reflect the latest developments in the field.
Position: Prospective of Autonomous Driving-Multimodal LLMs World Models Embodied Intelligence AI Alignment and Mamba
Yunsheng Ma*, Wenqian Ye*, Can Cui*, Haiming Zhang*, Shuo Xing*, Fucai Ke*, Jinhong Wang*, Chenglin Miao*, Jintai Chen, Hamid Rezatofighi, Zhen Li, Guangtao Zheng, Chao Zheng, Tianjiao He, Manmohan Chandraker, Burhaneddin Yaman, Xin Ye, Hang Zhao, Xu Cao (* equal contribution)
The 3rd WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD) 2025
In this paper we provide an outlook on this field summarizing existing methods and exploring their limitations. In addition we further discuss the applicability of emerging approaches such as Reinforcement Learning from Human Feedback and Mamba for applications in autonomous driving. Finally we highlight open questions and offer insights into promising directions for future research. This paper is part of a living document that will be updated based on the LLVM-AD workshop series to reflect the latest developments in the field.

OpenEMMA: Open-Source Multimodal Model for End-to-End Autonomous Driving
Shuo Xing, Chengyuan Qian, Yuping Wang, Hongyuan Hua, Kexin Tian, Yang Zhou, Zhengzhong Tu
The 3rd WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD) 2025

Drawing inspiration from recent advancements in inference computing, we propose OpenEMMA, an open-source end-to-end framework based on MLLMs. By incorporating the Chain-of-Thought reasoning process, OpenEMMA achieves significant improvements compared to the baseline when leveraging a diverse range of MLLMs. Furthermore, OpenEMMA demonstrates effectiveness, generalizability, and robustness across a variety of challenging driving scenarios, offering a more efficient and effective approach to autonomous driving.
OpenEMMA: Open-Source Multimodal Model for End-to-End Autonomous Driving
Shuo Xing, Chengyuan Qian, Yuping Wang, Hongyuan Hua, Kexin Tian, Yang Zhou, Zhengzhong Tu
The 3rd WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD) 2025
Drawing inspiration from recent advancements in inference computing, we propose OpenEMMA, an open-source end-to-end framework based on MLLMs. By incorporating the Chain-of-Thought reasoning process, OpenEMMA achieves significant improvements compared to the baseline when leveraging a diverse range of MLLMs. Furthermore, OpenEMMA demonstrates effectiveness, generalizability, and robustness across a variety of challenging driving scenarios, offering a more efficient and effective approach to autonomous driving.
2024
Video Quality Assessment: A Comprehensive Survey
Qi Zheng, Yibo Fan, Leilei Huang, Tianyu Zhu, Jiaming Liu, Zhijian Hao, Shuo Xing, Chia-Ju Chen, Xiongkuo Min, Alan C. Bovik, Zhengzhong Tu
Under review. 2024
We present a comprehensive survey of recent progress in the development of VQA algorithms and the benchmarking studies and databases that make them possible. We also analyze open research directions on study design and VQA algorithm architectures.
Video Quality Assessment: A Comprehensive Survey
Qi Zheng, Yibo Fan, Leilei Huang, Tianyu Zhu, Jiaming Liu, Zhijian Hao, Shuo Xing, Chia-Ju Chen, Xiongkuo Min, Alan C. Bovik, Zhengzhong Tu
Under review. 2024
We present a comprehensive survey of recent progress in the development of VQA algorithms and the benchmarking studies and databases that make them possible. We also analyze open research directions on study design and VQA algorithm architectures.

Plum: Prompt Learning using Metaheuristic
Rui Pan*, Shuo Xing*, Shizhe Diao*, Wenhe Sun, Xiang Liu, Kashun Shum, Jipeng Zhang, Renjie Pi, Tong Zhang (* equal contribution)
Findings of the Association for Computational Linguistics (ACL Findings) 2024

In this paper, we introduce metaheuristics, a branch of discrete non-convex optimization methods with over 100 options, as a promising approach to prompt learning. Within our paradigm, we test six typical methods: hill climbing, simulated annealing, genetic algorithms with/without crossover, tabu search, and harmony search, demonstrating their effectiveness in white-box and black-box prompt learning. Furthermore, we show that these methods can be used to discover more human-understandable prompts that were previously unknown in both reasoning and image generation tasks, opening the door to a cornucopia of possibilities in prompt optimization.
Plum: Prompt Learning using Metaheuristic
Rui Pan*, Shuo Xing*, Shizhe Diao*, Wenhe Sun, Xiang Liu, Kashun Shum, Jipeng Zhang, Renjie Pi, Tong Zhang (* equal contribution)
Findings of the Association for Computational Linguistics (ACL Findings) 2024
In this paper, we introduce metaheuristics, a branch of discrete non-convex optimization methods with over 100 options, as a promising approach to prompt learning. Within our paradigm, we test six typical methods: hill climbing, simulated annealing, genetic algorithms with/without crossover, tabu search, and harmony search, demonstrating their effectiveness in white-box and black-box prompt learning. Furthermore, we show that these methods can be used to discover more human-understandable prompts that were previously unknown in both reasoning and image generation tasks, opening the door to a cornucopia of possibilities in prompt optimization.
2023
Optimality of the rescaled pure greedy learning algorithms
Wenhui Zhang, Peixin Ye, Shuo Xing
International Journal of Wavelets, Multiresolution and Information Processing 2023
We propose the Rescaled Pure Greedy Learning Algorithm (RPGLA) for solving the kernel-based regression problem. The computational complexity of the RPGLA is less than the Orthogonal Greedy Learning Algorithm (OGLA) and Relaxed Greedy Learning Algorithm (RGLA), and the convergence rate can be arbitrarily close to the best rate under a mild assumption of the regression function.
Optimality of the rescaled pure greedy learning algorithms
Wenhui Zhang, Peixin Ye, Shuo Xing
International Journal of Wavelets, Multiresolution and Information Processing 2023
We propose the Rescaled Pure Greedy Learning Algorithm (RPGLA) for solving the kernel-based regression problem. The computational complexity of the RPGLA is less than the Orthogonal Greedy Learning Algorithm (OGLA) and Relaxed Greedy Learning Algorithm (RGLA), and the convergence rate can be arbitrarily close to the best rate under a mild assumption of the regression function.